

|
A Year of Statistics in an Hour or Two: Heavy on Vocabulary, Light on Computation, No Counting Theory Designed as a one hour talk/intro, for someone with an 8th grade math background. This page is heavy on the pictures, but, light on the computation. There's no permutations, combinations, counting theory. There are links to this stuff. For just the vocabulary from this page, "A Year of Statistics in an Hour or Two," go to Statistics Vocabulary. For statistics resources go to MIDDLE GROUND, the statistics info page. |
| Support Stuff/Down Load Material
Here's the spreadsheet used for this page. Here is the pdf file of this page in case you wish to take notes. Here is a link to where the video of this page is stored. |
Discrete or Continuous  Click on the image to enlarge it. If you do decide to do a statistical study, two different types of data are obtained/used/needed. The type that is collected depends on what you are measuring, or counting, or observing. The two kinds of data are continuous and discrete. Your only task as we begin to analize data is to take note of what data is continuous and what is discrete. Vocabulary
|
| Look at the Data
Even before you look at the samples, what do you know?
You can tell if the sample is of continuous or discrete data. Which are which? Swipe between the stars below to see the answers.
You are now ready to example the data and statistics and displays. Do this THOROUGHLY AND ONLY ONE AT A TIME. Once you have done this answer some questions and review the vocabulary. Questions (Swipe between the stars below to see the answers.)
Vocabulary
|
|
Theoretical vs Experimental & Descriptive vs Analytical Statistics Thus far only experimental and descriptive statistics (statistics where data is collected, analysed, depicted, and described) has been used. Before analytical statistics (statistics where judgements are made) can be discussed, theoretical statistics (statistics where mathematics and common sense are used to examine a situation) must be discussed. Your job is to see if common sense and the theoretical statistics agree. A tree diageam is a paper and pencil way of figuring out the sample space ( the set of all possible results of an experiment). You can probally guess what each experiment was. Do common sense and the theoretical statistics agree? 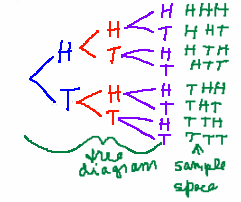
 Why bother with the tree diagram if you can list the sample space in your head? There are reasons:
Vocabulary
|
| Probability
Before going on, review new vocabulary and vocabulary already discussed.
Here's the new stuff.
Here's the answers to some problems. Here are blank problems. 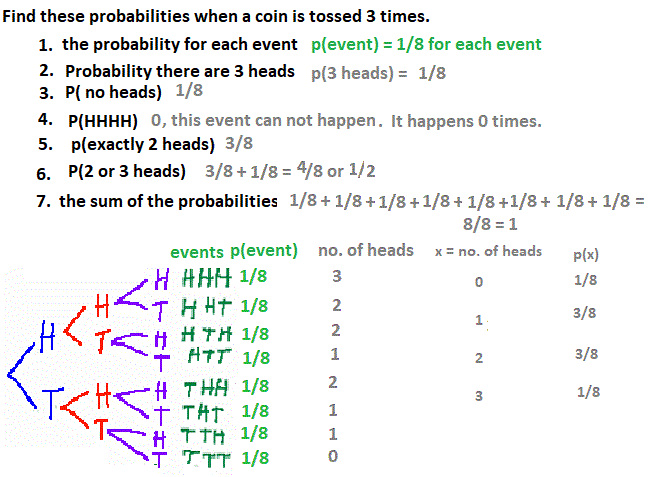 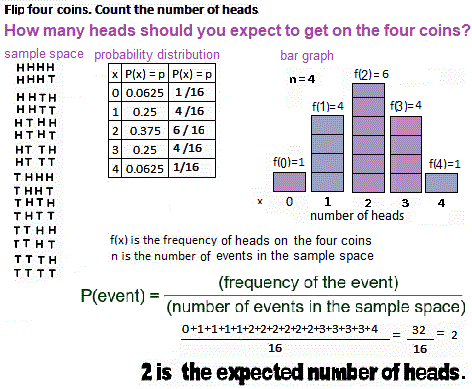 Vocabulary
|
|
More Vocabulary and Topics that Are Not Included on this Page
The first 7 definitions are important and understandable without computation. The last definitions can not be discussed well, without computation. As promised, these are left out of this page, but references are linked. Vocabulary 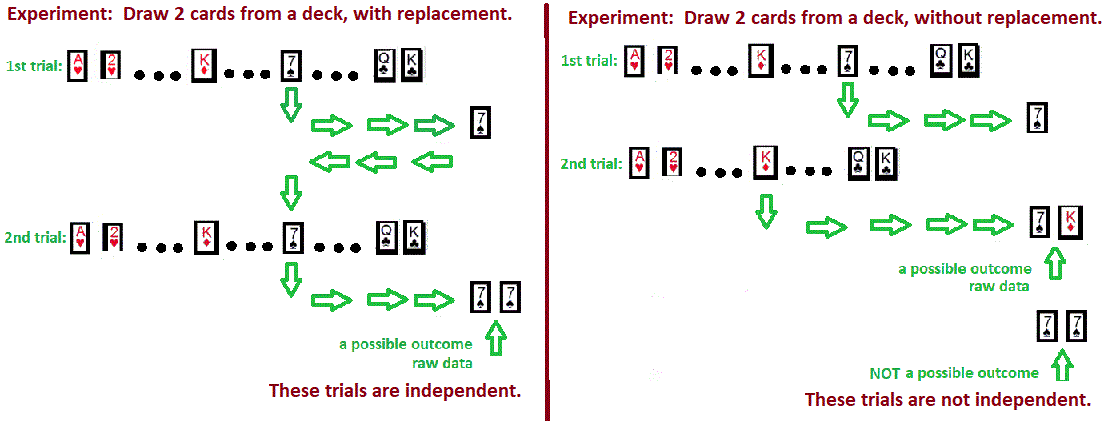
|
The Binomial Distribution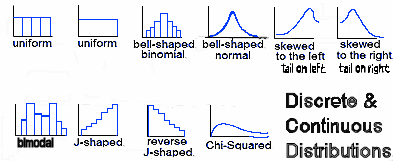 Distributions, ways the data in a population is centered and spreads out, have already have been introduced. Now consider one of those distributions in more detail, the Binomial Distribution. 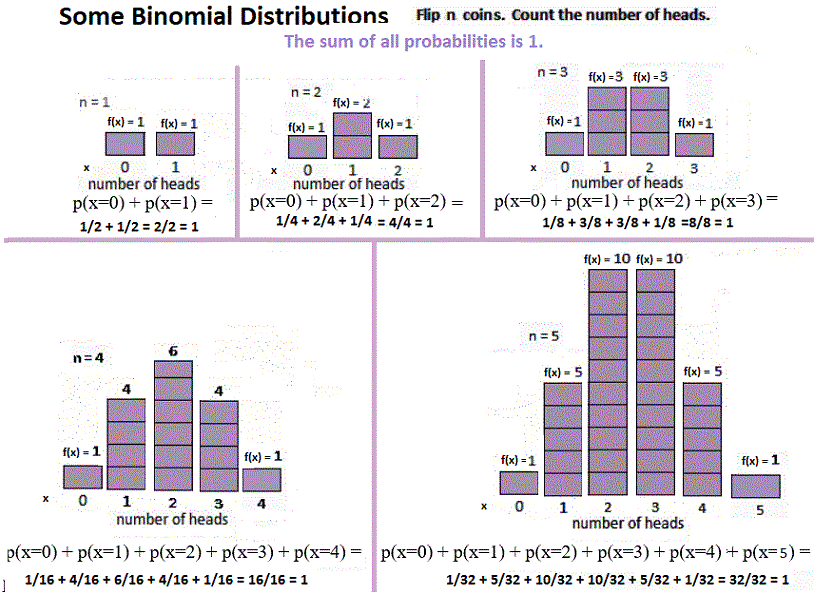 The binomial is a discrete distribution. Raw data is the number, x, of either successes on n identical, independent trials. Again that's: Binomial distributions have:
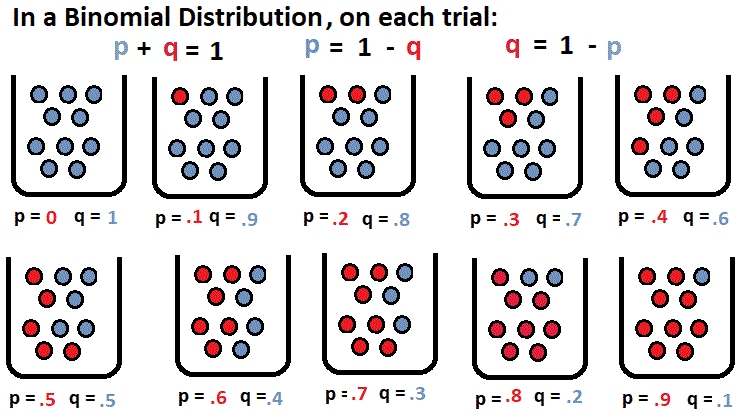 Probability statements look like p(x=3), meaning the probability of getting exactly 3 heads on n trials. The mean and standard deviation of a BINOMIAL DISTRIBUTION are stated below. For an intro to the binomial here's the link. For info on the formulas , click the formulas below. It is all on the same page.  Think that flipping coins are the only binomial distribution? How about a real-world problem. "Twenty phones have been poorly built. There's a 70% probability that a phone will work when it is switched on. What's the probability that at most half of the machines will run?" Notice that p is now .7 and you now have 20 trials. Harder problem. This kind of problem has not been covered. In symbols: Find p(x < 10), p= .7, n=20. Vocabulary
|
|
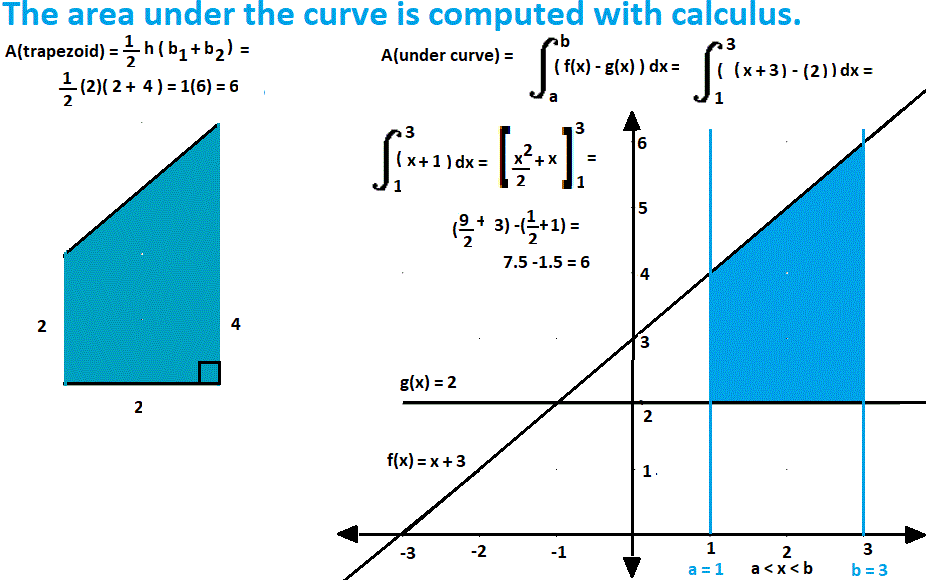
Thank Goodness for Probability Density Functions
Here's a problem for you to do without calculator or computer or spreadsheet:
In symbols:
 I promised light on the computation, so if you want to look at these problems, go to: Binomial Formula Explained.
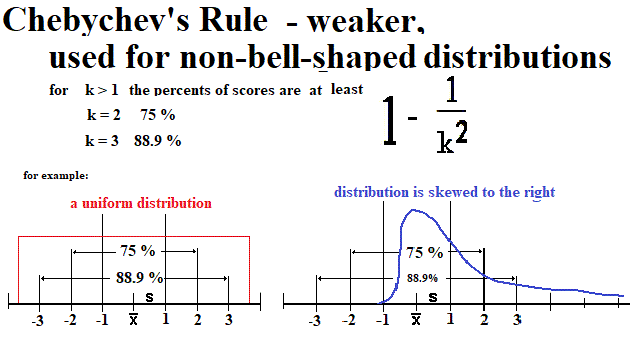
In 1733, Abraham de Moivre (1667 - 1754) was studying expanding binomials, as in (x + y) 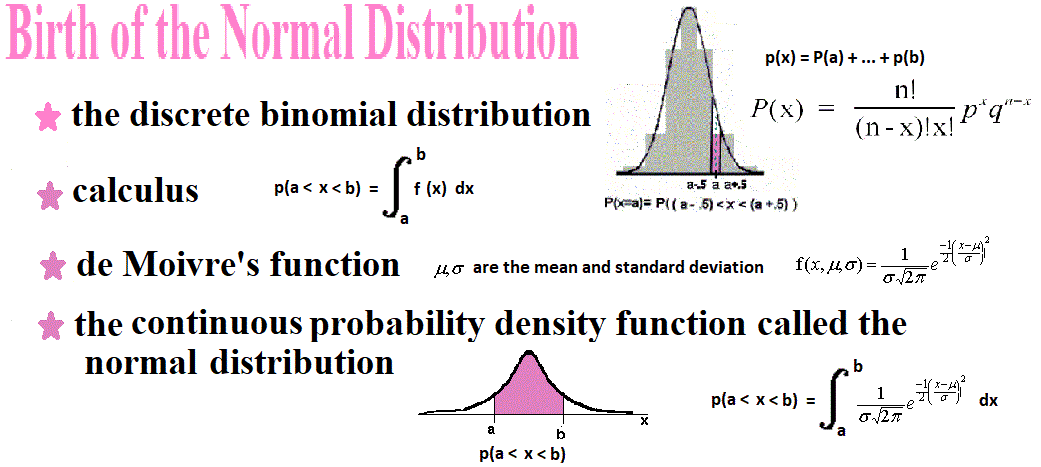 Johann Carl Friedrich Gauss (177-1855) later worked with the normal distribution. It is named for him. It is also called the bell curve. It is discussed below. Vocabulary
|
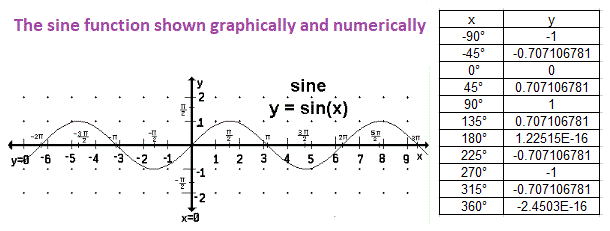
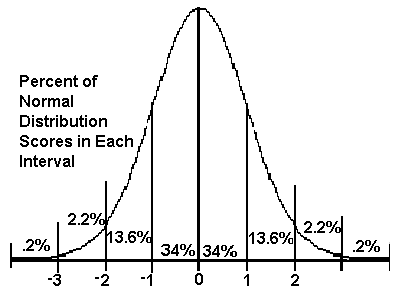
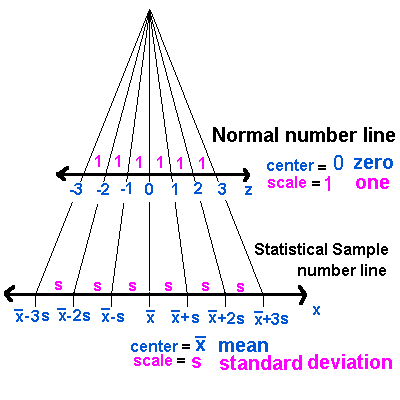
Normal and Standard Normal Distributions
The variables are x,
In this area of this page, population and sample mean and standard deviation symbols are used. Samples from a normally distributed population will be assumed to be normal also.
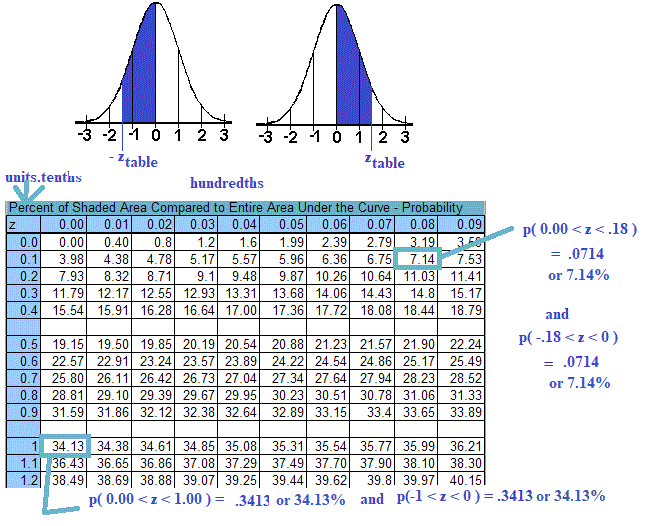
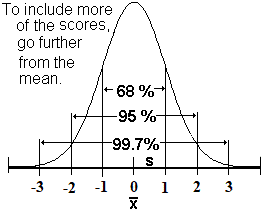
The Standard Normal Distribution
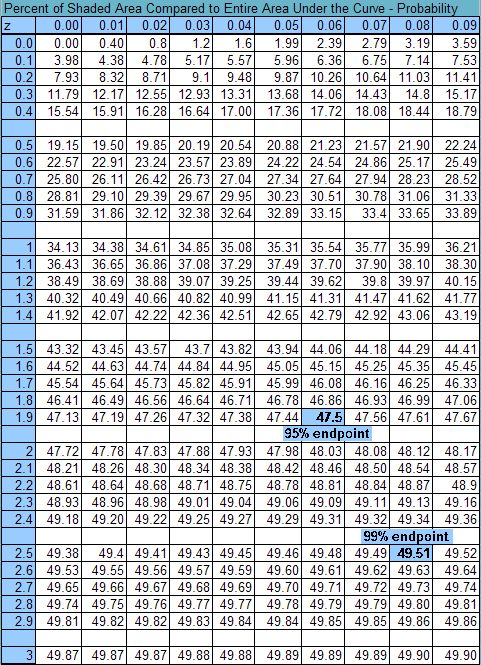
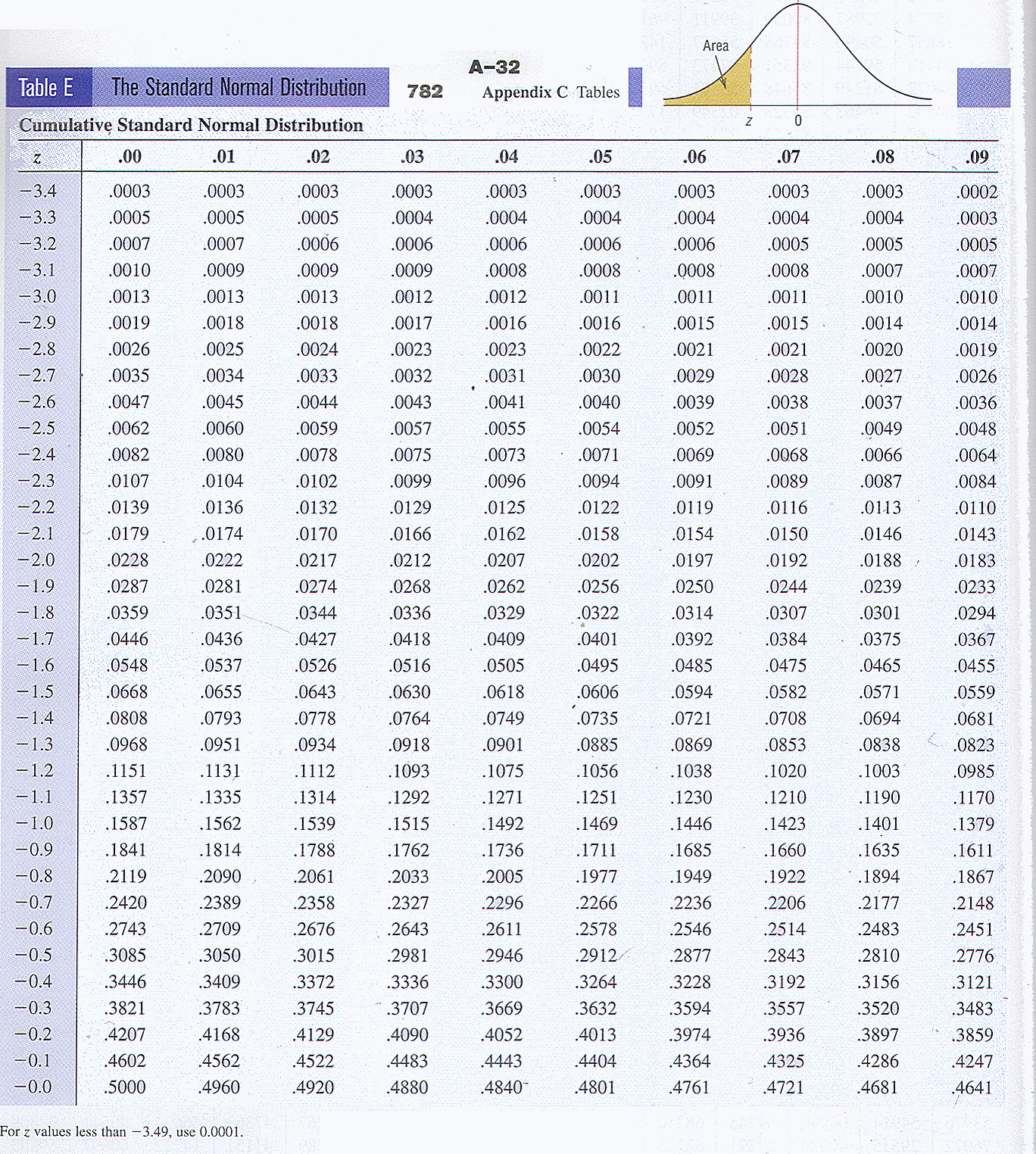
Two very useful formulas make it easy to translate x scores into z scores or z into x. Below the calculators do the work for you. Use the percent images above and mental computation or the calculators to answer the questions below the calculators.
Vocabulary
|
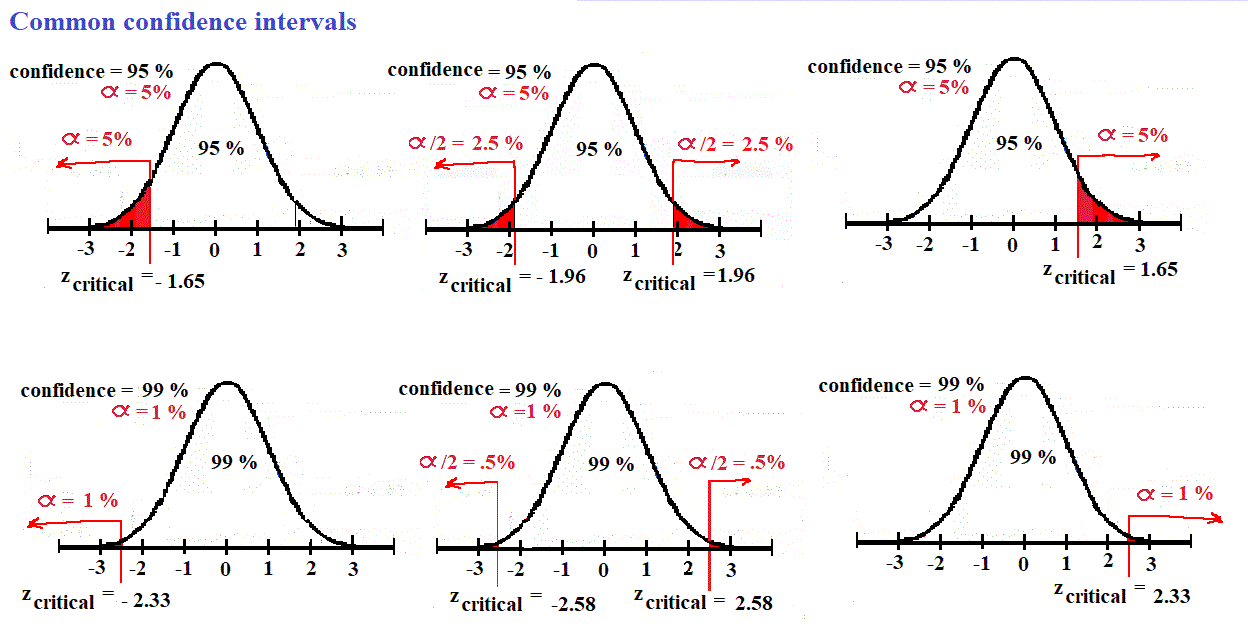
| Confidence Interval Before making a claim, most people like to be sure, or pretty sure, the statement is true. The statement might be about the mean of the population being sampled, or a belief one treatment has a higher mean than another, or that the means of 3 or more populations are the same. One might be 90% confident or sure about the statement, 95% condifent, etc. The larger the sample, the more sure or confident one would be about one's statement. Making a statement and stating how confident one is about the statement go hand-in-hand in statistics.
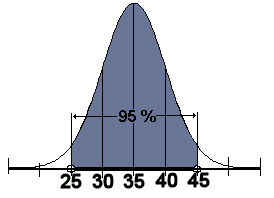
From 25 to 45 is the confidence interval for this normal distribution having a 95 % level of confidence. A confidence interval is the range of score in which you believe the population parameter is found. If the confidence interval accounts for 95 % of the scores, what percent of the scores under the density function are not in the interval, but out in the tails?
Vocabulary
|
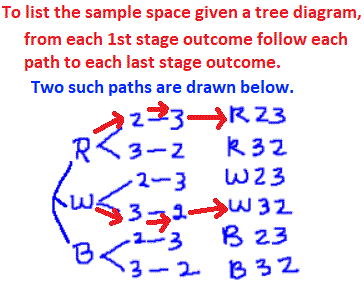
Hypothesis Testing
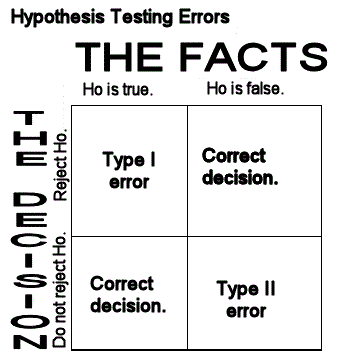
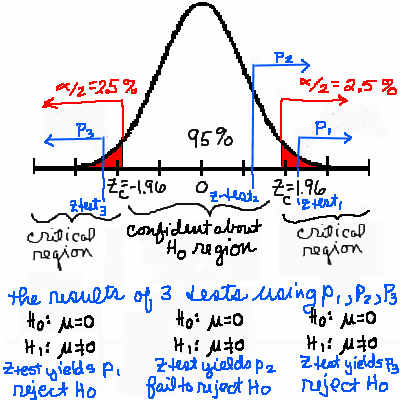
You say, "No. They are fine. They're still on average 70 mm long." "Ok. We need more information," said the mother. "One of my former students sold us the fish. He was really into statistics and wrote some population parameters on the receipt which I kept." "Your fish tank population mean length was 70 mm, which you already knew. The population standard deviation was 12 mm and you got about 80 fish." "Take 36 fish for a sample. Measure them as accurately as you can. We'll assume the population is normal and you can run a Hypothesis Test so we can make a judgement based on statistics. Here's a formula for your test statistic. When you finish, we'll see about the fish." 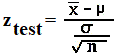 You have no idea what she's talking about! Before examining how to complete a hypothesis test, examing closely the picture below. Click on the picture to enlarge it. 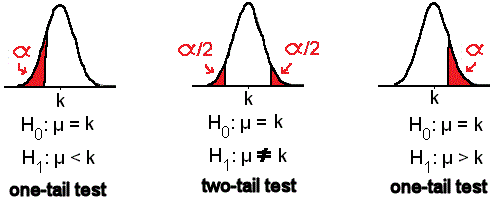
A hypothesis test is a procedure by which a hypothesis (or statement) which one believes to be true is tested statistically against another hypothesis already in use. Before clarification of this, some questions.
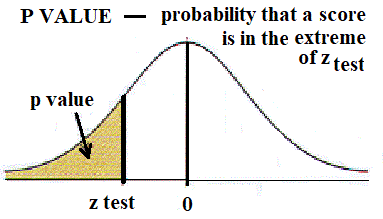
The calculator below has been provided to do the computation for you. Please use it to compute ztest.
There are many different hypothesis tests because there are many situations in which new information or verification is desired. We have been looking at a Z-Test for Normal Density Functions. For additional information on how to run a test see Hypothesis Testing. Before continuing, a summary of a test is needed. You need:
Now, examine other hypothesis tests the web page, or, HYPOTHESIS TESTS pdf file or video about the HYPOTHESIS TESTS pdf file, yes, a video about a pdf file, filed with other videos. You have completed "A Year of Statistics in an Hour or Two." Stay safe. --A2 Vocabulary
| ||||||||||||||||||||||||||||
Vocabulary
|
![[MC,i. Home]](http://www.mathnstuff.com/math/spoken/here/1gif/mcihome.gif)
![[Table]](http://www.mathnstuff.com/math/spoken/here/1gif/table.gif)
![[Words]](http://www.mathnstuff.com/math/spoken/here/1gif/words.gif)
![[this semester's schedule w/links]](http://www.mathnstuff.com/gif/semestr.gif)
![[Good Stuff -- free & valuable resources]](http://www.mathnstuff.com/gif/goods.gif)
|
www.mathnstuff.com/math/spoken/here/2class/90/fish.htm |


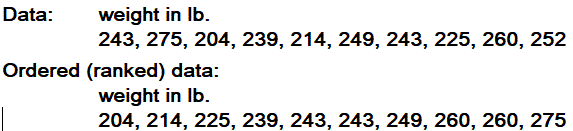

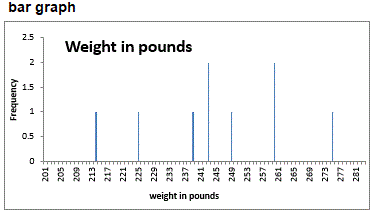
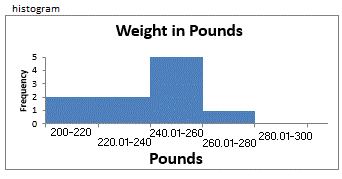
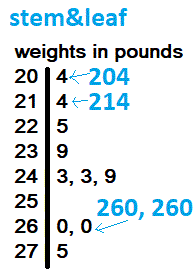
 - a math symbol meaning "add up the terms."
- a math symbol meaning "add up the terms."
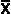 , read as "x bar" - arithmetic average. Formula:
, read as "x bar" - arithmetic average. Formula: 
 , read as "x hat" --median, Q2, the 50th percentile, the middle data point when the data is ordered
from lowest to highest
, read as "x hat" --median, Q2, the 50th percentile, the middle data point when the data is ordered
from lowest to highest
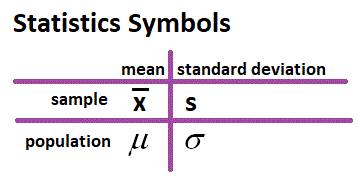


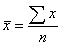 , the arithmetic average, the sum of the numbers divided by the number of numbers.
, the arithmetic average, the sum of the numbers divided by the number of numbers.
 =
= 
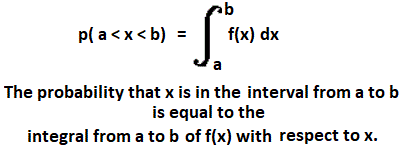
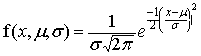
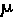 ,
,
 ).
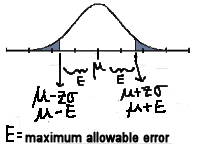
). . This is needed because there are really a whole family of normal distributions, each with their own mean and
standard deviation, but having the same features.
. This is needed because there are really a whole family of normal distributions, each with their own mean and
standard deviation, but having the same features.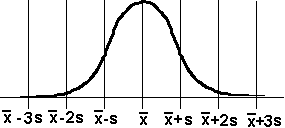


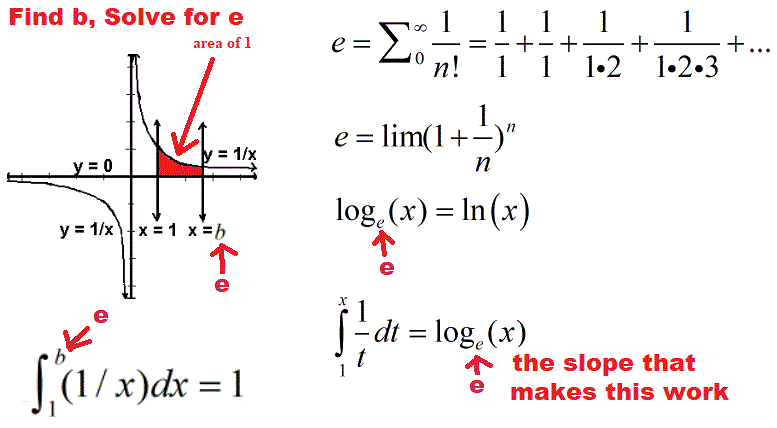
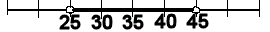


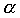 (alpha) - the area under the density function which is not in the confidence interval.
(alpha) - the area under the density function which is not in the confidence interval.

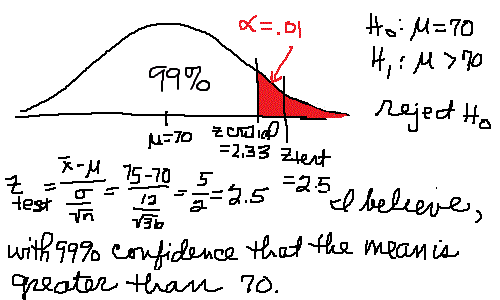
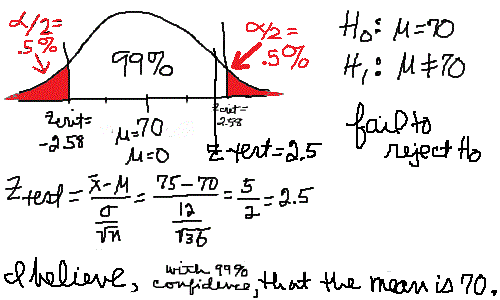
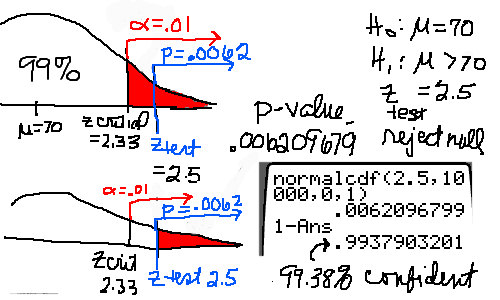
 k, where k is the null hypothesis mean.
k, where k is the null hypothesis mean.